Los árboles Merkle son una estructura de datos creada con el objetivo de facilitar la verificación de grandes cantidades de datos organizados relacionando los mismos por medio de diversas técnicas criptográficas y de manejo de información.
Dentro de cualquier bloque de la red Bitcoin nos encontramos con una estructura denominada «Árbol de Merkle».
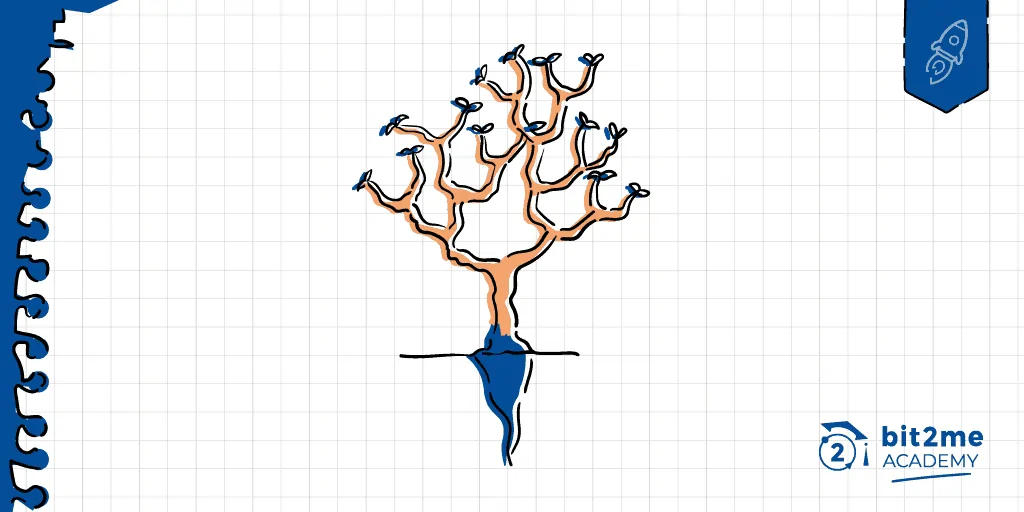
Un árbol Merkle, es una estructura de datos divida en varias capas que tiene como finalidad relacionar cada nodo con una raíz única asociada a los mismos. Para lograr esto, cada nodo debe estar identificado con un identificador único (hash). Estos nodos iniciales, llamados nodos hijos (hojas), se asocian luego con un nodo superior llamado nodo padre (rama). El nodo padre, tendrá un identificador único resultado del hash de sus nodos hijos. Esta estructura se repite hasta llegar al nodo raíz o raíz Merkle (Merkle Root), cuya impronta está asociada a todos los nodos del árbol.
Gracias a esta estructura única, los árboles Merkle permiten relacionar una gran cantidad de datos en único punto (Merkle Root). De esta forma, la verificación y validación de esos datos, puede pasar a ser muy eficiente, al tener que solo verificar el Merkle Root en lugar de toda la estructura.
Este diseño fue creado por Ralph Merkle, en el año de 1979, con el fin de agilizar el proceso de verificación de grandes cantidades de datos.

¿Cómo funciona un árbol Merkle?
Un árbol Merkle es una estructura que relaciona todas las transacciones y las agrupa entre pares para obtener un Root Hash o "dirección raíz". Este Root Hash, está relacionado con todos los hash del árbol. Verificar todas las transacciones de una red sería algo extremadamente lento e ineficiente. Por esta razón, se implementó este sistema. Ya que, si un hash es cambiado, cambiarían todos los demás hasta llegar a la raíz (root hash). Esto invalidará la autenticidad de la información de todo el árbol. Es precisamente esta función, la que permite a los árboles Merkels otorgar el alto nivel de seguridad que los caracteriza.
Para entender cómo funciona un árbol Merkle más en profundidad, examine el siguiente ejemplo:
Imagine un bloque de datos el cual lleva una impronta o hash único e irrepetible. Cada uno de estos bloques está organizado en capas en lo que veríamos como una estructura piramidal. Estos bloques están vinculados hacia una capa superior por medio de estos hashs. De esa manera, los bloques superiores señalan siempre a los bloques inferiores, pero más importante aún, es que el hash de estos bloques superiores es el resultado de la suma de la información que contiene el nuevo bloque con el hash del bloque anterior. De esa forma, al seguir escalando, la misma estructura se repite mientras se conectan todos los bloques a un gran bloque de datos.
El hecho de que funcione de esta manera, hace que la alteración del hash de un bloque, invalide los hashes del resto de los bloques. De esta forma el sistema facilita dos cosas. En primer lugar, facilita la verificación de los bloques de datos. En segundo lugar, sirve de mecanismo para evitar la manipulación. Esto gracias a que este mecanismo permite detectar cambios de hashes en cada bloque de datos. De detectarse un cambio, se invalida todo el árbol pues ha sido alterado y sus datos no son válidos.

Características de los árboles Merkle
Algunas de las características más destacables de los árboles Merkle son:
- Son un medio eficiente para generar una estructura distribuida de datos.
- Proveen de una gran seguridad y resistencia a alteraciones de datos.
- Permiten un alto nivel de rendimiento de transmisión de datos en redes distribuidas. Gracias a esto, disminuyen la cantidad de datos necesarios para su correcto funcionamiento.
- Son computacionalmente poco costosos y eficientes a la hora de crear, procesar y verificar información.
- Permiten "disección" para hacer búsquedas de verificación más rápidas. Todo ello, sin comprometer la seguridad y trazabilidad de las transacciones que se realicen.
- Gracias a la característica de "disección" también son capaces de permitir ahorrar recursos de almacenamiento.
- Ofrecen una gran adaptabilidad a distintos problemas informáticos. Gracias a esto, los árboles Merkle han sido ampliamente utilizados en distintos sistemas. Por ejemplo, software de base de datos, sistemas de archivos, estructuras de llaves públicas, sistemas de versionamiento, redes distribuidas (P2P), entre otros.
Usos en la actualidad
Los árboles Merkle en la actualidad tienen una amplia cantidad de usos en sistemas informáticos, y aquí hablaremos de algunos de ellos.
Tecnología blockchain
El uso de los árboles Merkle en la tecnología blockchain es vital. Gracias a su uso, el software cliente puede descargar todo el historial de la blockchain y verificarlo en caliente. De hecho, su uso facilita el proceso al permitir «podar» (tomar solo una parte del historial) el historial y reducir el tamaño de la descarga.
Por ejemplo, un usuario que desea instalar un cliente Bitcoin no tiene porque descargarse todo el historial de la blockchain. En lugar de eso, puede reducir su descarga a solo unos cientos o miles de bloques atrás. De esta forma, tiene acceso a una versión más ligera del historial que se ajusta más a sus requerimientos.
Al contrario de lo que puedan pensar esto no resta seguridad al cliente. Pues gracias al árbol Merkle, es posible bajar un «root hash» específico y desde allí comenzar a crear un historial. Como ese «root hash» está relacionado con los bloques anteriores a él, lo único que debe hacerse es verificarlo. Para ello, se puede acudir a una serie de nodos completos de Bitcoin (con todo el historial) y verificar que el «root hash» tomado coincida. Teniendo absoluto consenso en este punto, se da el «root hash» como válido. Y desde ese punto, el usuario puede usar perfectamente su nuevo nodo cliente Bitcoin.
Sistemas de archivos
Otra utilidad que podemos ver de los árboles Merkle se refleja en los sistemas de archivos. Un sistema de archivos, es una estructura de datos que un sistema operativo utiliza para seguir la pista de los archivos que almacena. Normalmente esta estructura es aplicada sobre un disco duro e incluso dentro de las tarjetas de memoria que usan nuestros smartphones.
Algunas de estas peculiares creaciones hacen uso de árboles Merkle con el fin de manejar y garantizar el uso correcto de los datos almacenados. Casos especiales de mención en este grupo son los sistemas de archivos ZFS y btrfs.
ZFS conocido como Zettabyte File System, es considerado en el mundo de la informática como el mejor sistema de archivo. Sus capacidades superan por mucho a sus contrincantes más conocidos como NTFS, FAT, exFAT o ext3/4. Cuenta con resistencia a fallos, recuperación y corrección de errores, de-duplicación de datos, replicación, copy-on-write (CoW) y una alta escalabilidad. Todo esto lo hace una opción perfecta para ser desplegado en ambientes críticos. Diseñado por Sun Microsystems y presentado en 2004, de momento es el líder de los sistemas de archivos para computadores.
Pero para lograr esto ZFS tiene una herramienta secreta en medio de todo su código: el uso extensivo e intensivo de árboles Merkle. Todo esto con el fin de contar con un sistema que permita la rápida verificación de los datos que almacena dentro de sus estructuras. Sus propiedades de recuperación de errores, de-duplicación, CoW (Copy-On-Write) y replicación dependen fuertemente de esta técnica, pues de otra forma, supondría un elevado coste computacional que echaría por tierra sus ventajas.

Sistemas de control de versiones
Otro uso de los árboles Merkle lo podemos ver en los sistemas de versionamiento de software, casos muy conocidos de Git y Mercurial. De ambos, el más ampliamente conocido en Git, el mismo que posibilita el funcionamiento de plataformas como Gitlab y Github, o el desarrollo del kernel Linux, este último fue el primer proyecto en usarlo en producción, pues el creador de Git es Linus Torvalds.
El uso de los árboles Merkle en este tipo de software viene relacionado con el sistema de seguimiento de cambios dentro del repositorio o espacio de trabajo donde se almacenan los archivos. De esta forma, cada cambio realizado (bloques nuevos de datos) pasa por un proceso de hashing que al pasar por todo el contenido del repositorio, genera un hash único de dicho espacio de trabajo, que recibe el nombre de commit.
Este sistema de marcado nos permite por ejemplo, ir a un commit específico para ver cual era el estado del código del proyecto en un determinado momento, mientras que el estado general del proyecto se mantiene intacto. Viéndolo de una manera más sencilla, los árboles Merkle en Git nos permiten crear una especie de máquina del tiempo, que nos permite navegar por los distintos commit del proyecto, manteniendo los archivos y sus cambios tal cual como estaban en ese determinado momento.
Una utilidad que resulta muy útil a la hora de diseñar software en ambientes de trabajos distribuidos y de alto tráfico, tal y como no los ha demostrado Linus Torvalds en su grandioso proyecto del kernel Linux.